안녕하세요
푸디헬스입니다
오늘은 조건부 평균과 조건부 확률을 R을 통해 구해보도록 하겠습니다.
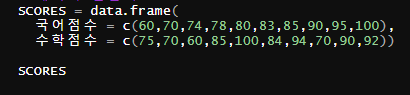
data.frame 함수로 데이터를 만들어줍니다.
평상시 가장 많이 사용되는 시험 점수 데이터입니다.
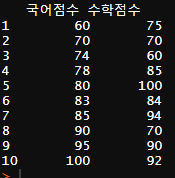
그러면 이와 같이 10행 2열의 국어 점수, 수학 점수 데이터가 생성이 됩니다.
여기서 저희는 상위권의 점수
수학 점수가 80점 이상인 데이터를 subset함수를 통해 추출해 보겠습니다.

MATH_GOOD에 SCORES데이터 중에서 수학점수가 80점 이상인 데이터를 넣습니다.
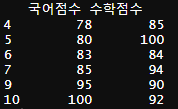
그러면 수학점수가 80점 이상인 점수 데이터만 추출이 됩니다.
여기서 저희는 국어 점수가 90점 이상인 데이터의 조건부 확률을 구해보겠습니다.
MATH_GOOD$국어 점수>=90의 결과는 FALSE FALSE FALSE FALSE TRUE TREU가 나오는데
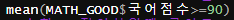
FALSE는 0이고 TRUE는 1이므로 mean함수를 쓰면 2/6이 되어 0.33333이라는 조건부 확률이 나오게 됩니다.
조건부 평균을 구할 때는 논리 연산만 빼주면 됩니다.

그래서 이 점수의 결과는 수학 점수가 80점 이상일 때 국어점수의 평균입니다.
이와 반대로 수학 점수가 80점 미만일 때 국어가 90점이상일 확률과
수학점수가 80점 미만일 때 국어 점수의 평균을 구하고 싶으면
MATH_BAD = subset(SCORES, 수학 점수 <80)
MATH_BAD
mean(MATH_BAD$국어 점수>=90)과
mean(MATH_BAD$국어 점수)
이렇게 코딩해주시면 됩니다.
이렇게 하면 조건부 평균과 조건부 확류 구하기는 끝이 납니다.
subset함수로 간단하게 구할 수 있죠??
지금부터는 간단한 회귀모형에 대한 코딩을 해보겠습니다.
단순 회귀모형은 simple regression model이라고 부르고 회귀분석의 기초가 되는 모형입니다.
기본적으로 목표가 되는 값을 y라고 했을 때 y에 영향을 끼치는 x(원인) 간의 함수관계를 설명하기 위해서 회귀분석을 합니다.
분석을 하기 전까지는 x와 y사이에 어떠한 관계가 있는지는 모르지만 데이터를 통해 임의의 모델을 선택해 하나의 직선을 만들어 냅니다. 이를 선형 회귀(linear regression)라고 합니다. 선형 회귀모형 이외에 다중 선형 회귀모형 같은 다른 모형도 있지만 가장 간단한 linear regression을 해보겠습니다.

일단 데이터를 먼저 불러와야 하기 해서 read.csv함수를 썼습니다.
그리고 그 데이터를 heights에 넣었어요. 데이터를 csv(엑셀) 데이터를 불러오는 방법은 Chapter 3에 있습니다.
nrow(heights)로 데이터의 개수를 파악하고, 빅데이터이기 때문에
head(heights)로 데이터의 일부분만 확인해줍니다.

그런 다음 빅데이터를 plot에 찍어보겠습니다.
plot을 이용해 x축에 father의 heights를 y축에 son의 heights를 pch(point character)=16으로 하고
col = '#3377 BB77'로 했습니다. #3377 BB77은 나중에 color 포스팅에서 따로 다뤄보도록 하겠습니다.
일단은 투명도와 색을 지정해주는 문법 정도라고 알아두시면 되겠습니다.
그리고 난 뒤 abline을 이용해 father의 평균을 가로 세로로 그어주었습니다.

그리고 lm(Linear regression model) 함수를 이용해 선형 회귀 분석을 합니다
lm(관심 있는 변수 ~ 설명변수, data = 데이터)를 넣는 형식입니다.
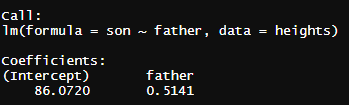
lm_heights를 실행하면 왼쪽처럼 나오게 됩니다.
관심 있게 볼 부분은 coefficents부분으로
y = 86.0720 + 0.5141 * x라는 의미입니다.
son heights = 86.0720 + 0.5141 * father heights라는 의미입니다
즉 86에 아빠 키의 절반 정도를 더한 것이 아들의 키라는 의미죠.
예를 들어 아버지의 키가 180이라면 아들의 키는 86 + 90 = 176 정도라는 의미입니다.
를 실행하면 밑과 같이 다양한 숫자들이 나옵니다
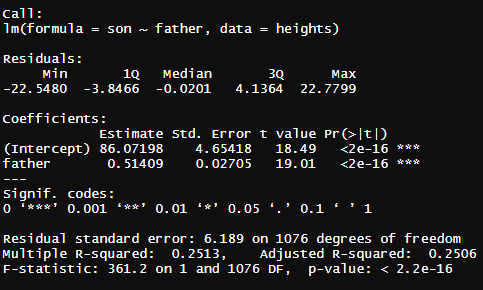
여기서 관심 있게 볼 부분은
estimate 아랫 값인 회귀 계수
저희가 위에서 보았던 숫자인 86.07198
0.51409입니다.
여기서 밑에서 2번째 줄인 Mutiple R-squared : 0.2513이란 느 수치가 있는데
이는 쉽게 설명하면
아들 키의 차이를 100이라고 하면 아버지의 키를 가지고 설명 가능한 정도는 25%라는 의미입니다.
그래서 이것을 plot에 최종적으로 표현하면

코드는 이렇게 되고 그림은!
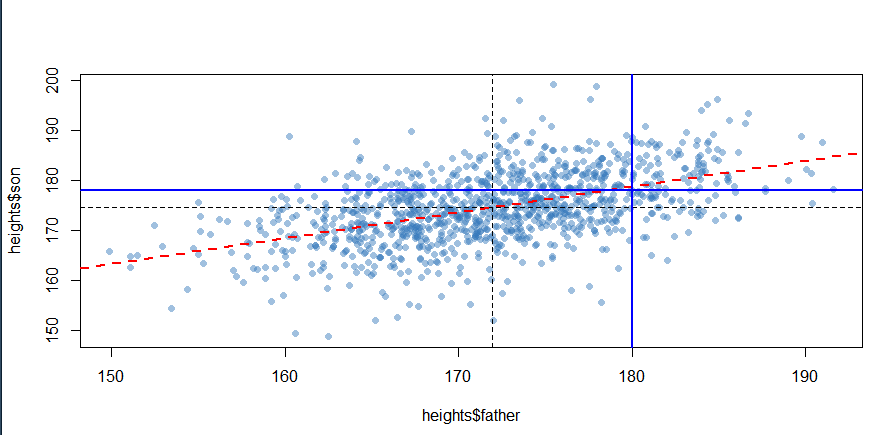
이런 식으로 나옵니다. 파란선의 교차점이 빨간 점과 약간의 차이는 있습니다.(제가 숫자를 대충 계산해서 그렇습니다.)
그래서 빨간 선은 son heights = 86.0720 + 0.5141 * father heights
이렇게 plot에 포 현까지 해주면 linear regression이 끝납니다.
회귀모형이라는 단어만 들었을 때는 어렵게 들리지만 막상 해보니깐 그렇게 어렵지는 않죠?
그럼 오늘은 간단한 선형 회귀분석을 해보았습니다.
다음 포스팅으로 찾아뵙겠습니다.
(회기역 근처에서 R 기초 과외하고 있으니 관심 있으신 분은 jwj4519@naver.com 또는 jwj4519(카톡 ID)로
연락 주시면 감사하겠습니다.)
좋은 하루 보내세요.^^




댓글